
Comparing Classical ML Models
Which model suits the dataset best?
Navigating through a plethora of machine learning models presents a challenge in identifying the optimal one for our dataset. Given the nature of our dataset, which entails cyberattacks on IoT devices, our focus is on discovering a machine learning model that not only delivers commendable performance but also operates efficiently with low memory usage on IoT devices. In our exploration, we aim to analyze the effectiveness of different algorithms across on classifying 2, 8, and 34 classes within the dataset.
Dataset
The dataset is comprised of various cybersecurity attacks against IoT devices, collected by The Canadian Institute for Cybersecurity (CIC IoT Dataset 2023).
When framing the classification problem, we decided to create three independent data-frames categorized into different classes.
2 Classes: This data-frame contains the dataset on labels which are either an Attack (malicious against IoT devices) or Benign (not harmful).
8 Classes: This data-frame contains the dataset on labels which are:
Benign (not harmful)
Distributed Denial-of-Service (DDOS)
Denial-of-Service (DoS)
Recon
Exploiting Web-Based Vulnerabilities
Spoofing Communication
Brute-Force
Mirai
34 Classes: This data-frame contains the dataset on all labels which can be found in more detail here
The Models
We trained 7 classical machine learning models:
Logistic regression
Adaboost
Gradient boost
K-nearest neighbours (KNN)
Support vector machines
Balanced support vector machines (BSVM)
Weighted support vector machines (WSVM)
XGBoost
Random forest
Default random forest
Weight-based balanced random forest
Bagging-based balanced random forest
Methodology
We first sampled 400,000 datapoints from the dataset, where the class distributions were preserved when under-sampling. We then distributed this into a 80% training set and a 20% testing set, which were normalized before the training process.
Building off the work from other sub-teams, we selected the most important 22 features to use in our dataset:
duration
srate
drate
syn_flag_number
psh_flag_number
ack_flag_number
ack_count
syn_count
rst_count
header_length
https
ssh
flow_duration
avg
max
tot_sum
min
iat
magnitude
radius
variance
We also kept as many hyper-parameters as possible in common between the models, where we kept each model the same for each classes (2 classes, 8 classes, 34 classes):
Logistic Regression: (C = 1, max_iter=500. solver=’lbfgs’, penalty=’l2’, random_state=42)
KNN: (n_neighbors = 8)
Support Vector Machines: (C=1, kernel = "rbf", gamma = "scale")
Random Forest: (n_estimators=100)
Adaboost: (n_estimators=100, learning_rate=1, random_state=42
)Gradientboost: (n_estimators=100, learning_rate = 1, max_depth = None)
XGBoost: (n_estimators=100, learning_rate = 1, booster = "gbtree", random_state = 42, max_depth = 13, max_samples = 0.9)
Default random forest: (n_estimators=100)
Weight-based balanced random forest: (n_estimators=100, class_weight="balanced")
Bagging-based balanced random forest: (n_estimators=100, sampling_strategy="all", replacement=True)
Evaluation Metrics
The evaluation of different ML models and configurations is conducted based on evaluation metrics. TP represents the True Positives, TN the True Negatives, FP the False Positives, and FN the False Negatives.
Accuracy: responsible for evaluating the classification models by depicting the proportion of correct predictions in a given dataset and is based on the following expression
\(Accuracy = \frac{TP+TN}{TP+TN+FP+FN}\)Recall: the ratio of correctly identified labels to the total number of occurrences of that particular label
\(Recall = \frac{TP}{TP + FN}\)Precision: the ratio of correctly identified labels to the total number of positive classifications
\(Precision=\frac{TP}{TP+FP}\)F1-Score: Harmonic mean of precision and recall for a more balanced summarization of model performance
\(2 \times \frac{Precision \times Recall}{Precision + Recall} = \frac{2TP}{2TP+FP+FN}\)
Results
{kind=link}
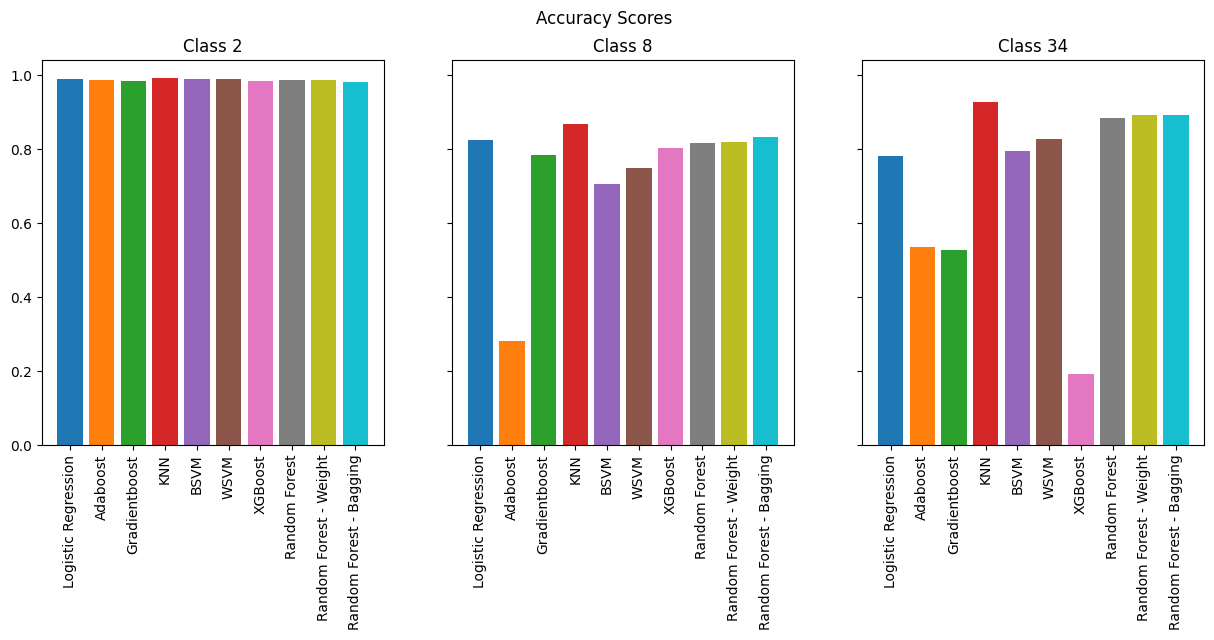
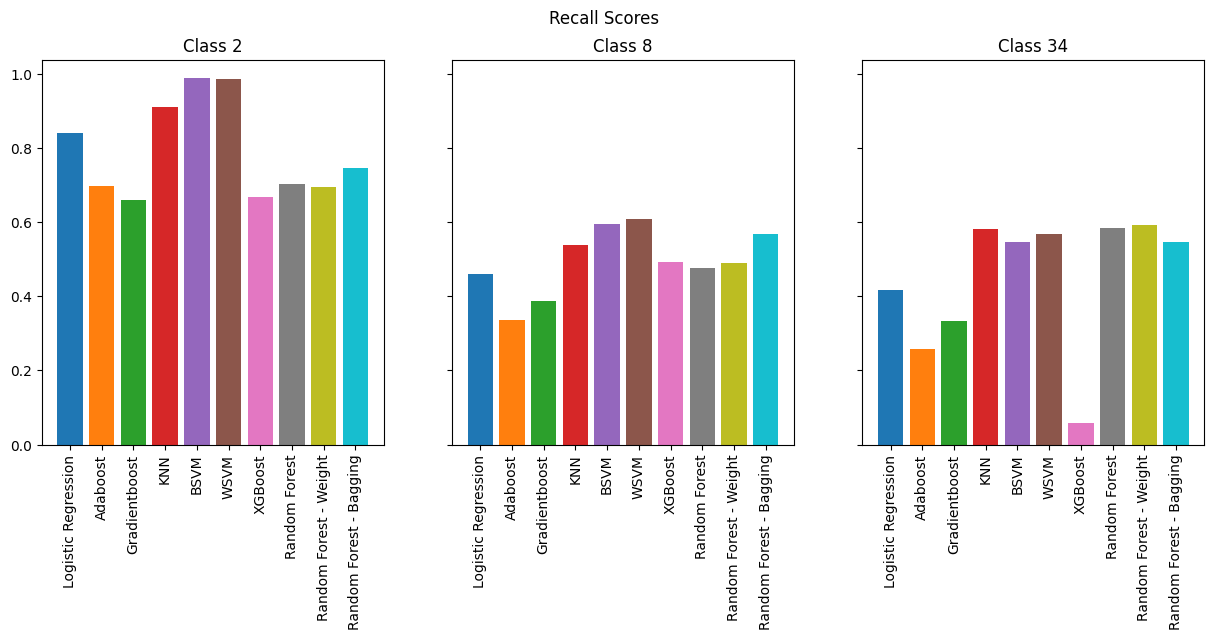
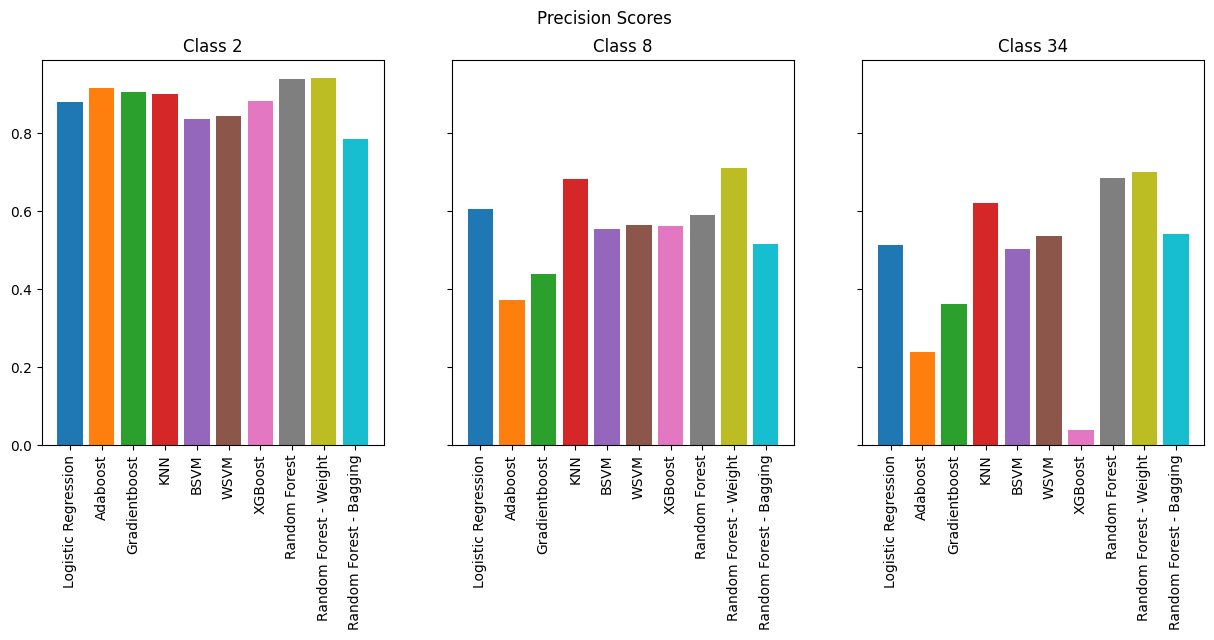
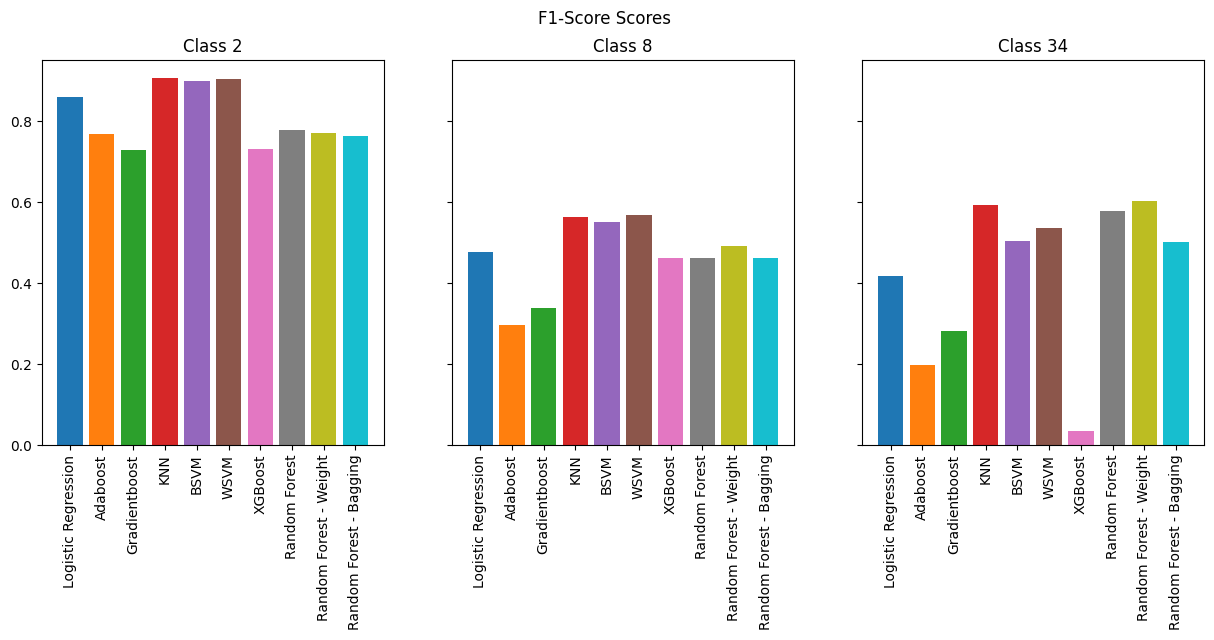
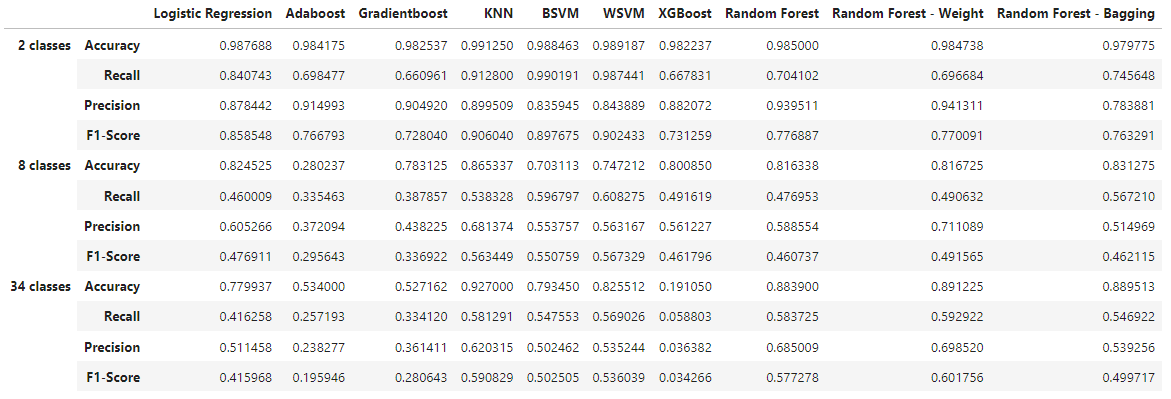
Overall, many models performed reasonably, like KNN, SVMs, and even Logistic regression. However we see that boosting methods performs horribly. The best performing model is by far random forests.
As expected, the models perform best for binary classification, especially in terms of accuracy where we see 98% across the board. However, when we look at F-1 Score, we see less consistency across the models. SVMs and KNN consistently perform the best, but it is important to note that they are memory-intensive compared to other models.
As we increase the number of classes, we observe that boosting methods are the worst performers while KNN and SVMs continue to perform well. However, if we are to take into consideration memory efficiency which is vital for running on an IoT device, Random Forests provide the best combination of performance and efficiency.
Discussion
To illustrate how these models are performing for each class, we can display the confusion matrix for K-nearest neighbours and Default random forests in the case of multiclass classification of 8 classes:
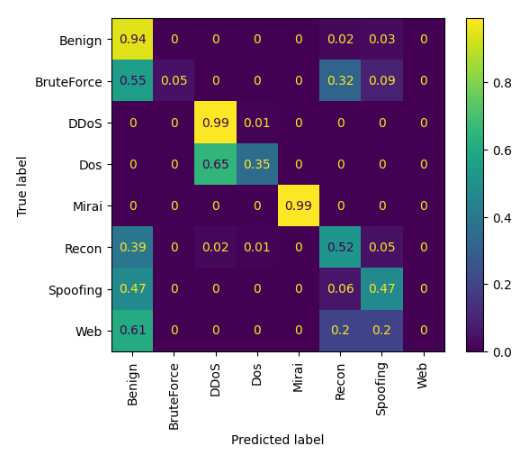
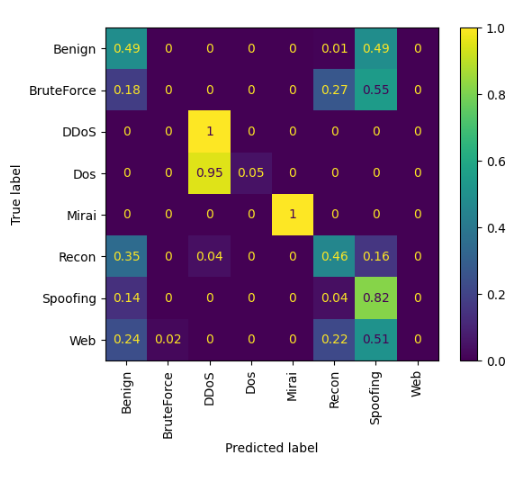
In both cases, it is possible to observe that some classes such as DDoS and Mirai are very well classified, usually those with very high support. On the other hand, classes such as Web and BruteForce have a very high misclassification rate due to having very low support.
Limitations
We ran our models on Kaggle, which was quite slow, taking over 10 hours for 400,000 datapoints
We used a small subset (5%) of the full dataset, with some classes having a support of <10 in the 34 class case, leading to poorer performance than if we had used the full dataset.
Some models (the Random Forest and XGBoost ones in particular) did not have an opportunity to go through a round of hyperparameter tuning, which means their performance is not as high as it could be
We did not consider the computational or memory costs of utilizing the models
Conclusion
In conclusion, the growing significance of the Internet of Things (IoT) in contemporary society underscores the need for robust security solutions. In our exploration of various machine learning models, we have discerned that random forests emerge as a particularly compelling choice. Not only do they exhibit computational and memory efficiency, but they also prove to be adept at classifying cybersecurity attacks on IoT devices. As the technological landscape continues to evolve, the deployment of random forests stands out as a strategic and efficient approach to fortifying IoT operations, ensuring their efficiency, security, and dependability.