
MLIR: the ML to Accelerator Toolkit
Let's see why this tool is exploding in popularity at AI accelerator companies
What is MLIR?
You might’ve seen companies like NVIDIA creating new AI accelerators (computer chips to run AI models faster than CPUs). ML libraries (like PyTorch, TensorFlow) can’t automatically run on all this new hardware. To support that, these companies need to build ‘compilers’. Compilers are just software that:
Convert normal torch/TF code to intermediate representation (IR). Code that does this is called the frontend compiler.
Optimise the IR to run faster with less memory. This is done by the middle-end compiler.
Lower the IR to hardware-specific instructions via the backend compiler.
MLIR (Multi-level intermediate representation) is a modern tool to build these compilers. It’s built on top of an older tool called LLVM.
LLVM vs MLIR:
LLVM produces IR with rigid/fixed operations and types. Ex: this shows individual integers being added or multiplied.
%1 = add i32 %a, %b ; Only supports basic types like i32
%2 = mul i32 %1, %c ; Has CPU-like (assembly language) operationsMLIR: Produces IR with flexible/custom operations and types. Ex: this shows a custom-defined convolution operation that acts on groups (tensors) of numbers.
%tensor = "ml.conv2d"(%input, %kernel) : (tensor<224x224x3xf16>, tensor<64x3x3x3xf16>) -> tensor<224x224x64xf16>This is why companies producing custom ML accelerators like MLIR. They can create hardware that supports specialised ML operations and produce compilers that can turn ML code into those specialised operations.
Converting Code to MLIR
The Building Blocks
Every MLIR instruction is an operation. It looks a little messy, but it basically lists all the features of functions in any programming language like python:

Though we can break down the mess into parts:
%t_tensor- this is the return value of the ‘function’ (operation)toy.transpose- this is the name of the operation%tensor- this is an input argument to the operation. There can be more than one{inplace = true}- this is a compile-time attribute. Compile-time just means the attribute won’t change while the code is running. It’s preset.(tensor…) → tensor…- this tells us the data type of the argument and the return. In this case, both tensors (groups of numbers), with different shapesloc(…)- this is debugging information that tells us where the ‘function’ (operation) was being used.
Anyways, this seems like a lot of information for each instruction. LLVM doesn’t seem so bad right now 😅 Luckily, MLIR lets us hide complexity with dialects.
Dialects: Custom Syntax
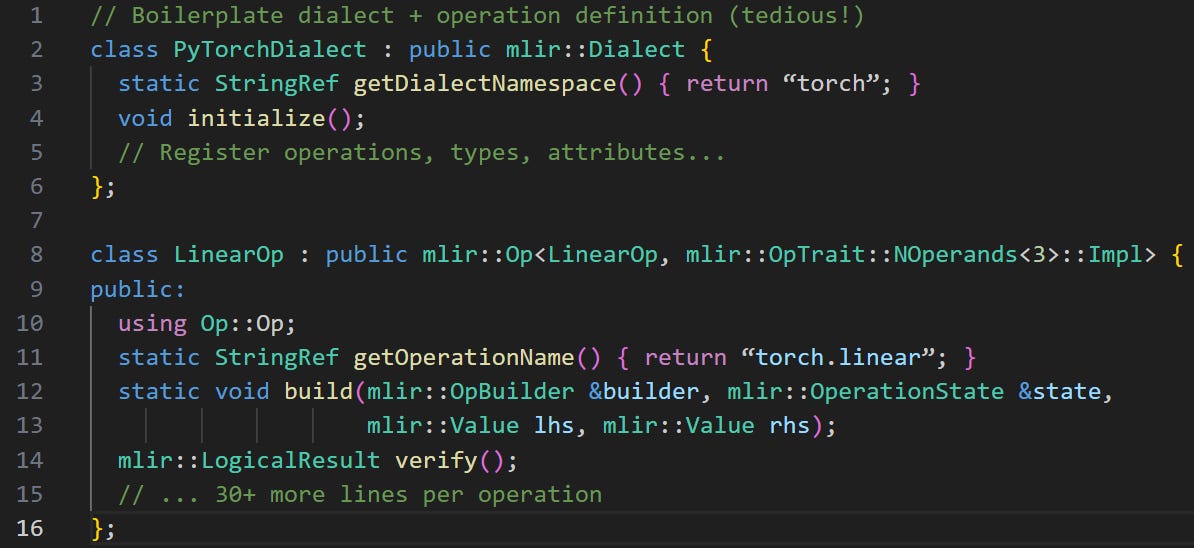
A dialect is a C++ class defining custom operations and syntax rules. It looks ugly:
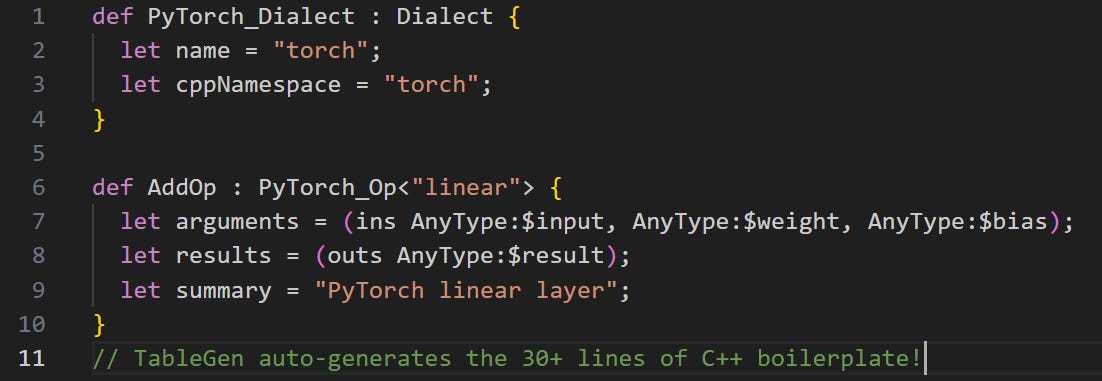
TableGen is an alternative format to specify these rules. It gets rid of all the clutter:
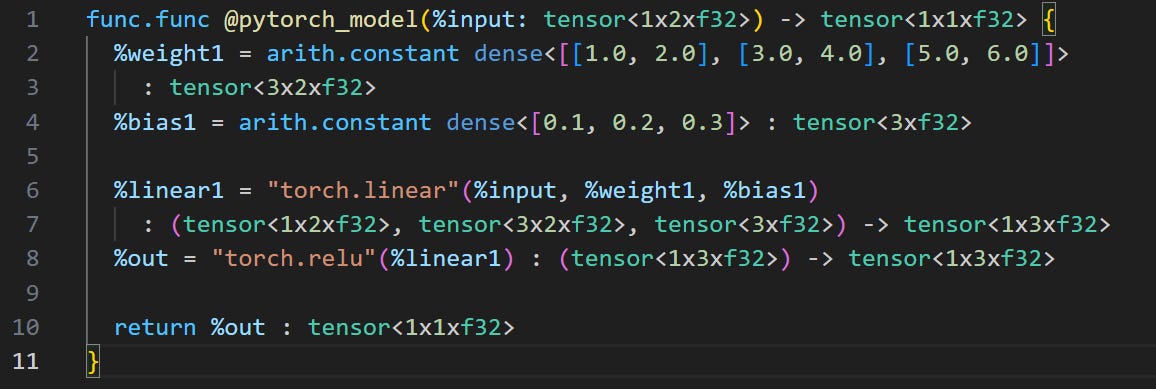
Result: Much more readable IR:
Regions and Blocks
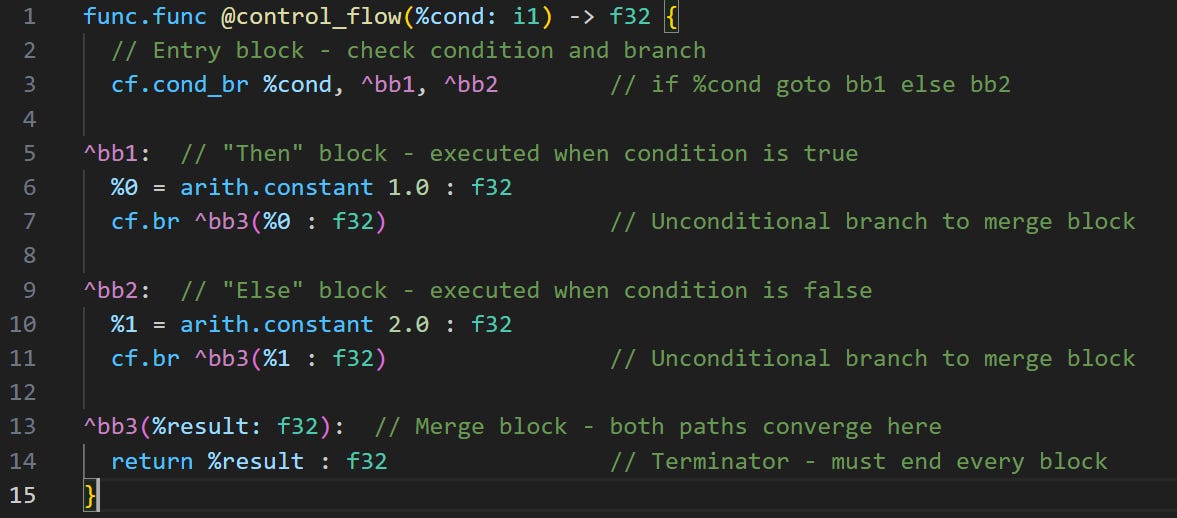
Operations are fine to represent step by step instructions. Though what about turning Pytorch/Tensorflow code with for loops or conditional statements into MLIR? Blocks and regions help with this:
Blocks are sequences of operations ending in a terminator (like the return line in a function)
Regions are collections of blocks (for control flow like if/else, loops)
PyTorch to MLIR
Now that we understand some of the basic building blocks above, we can convert Pytorch to an MLIR intermediate representation to optimise. Note that there’s a built-in tool in Pytorch to help: torch.fx. It represents pytorch code in a standardised graph. This graph is easier to process than raw Pytorch code alone.
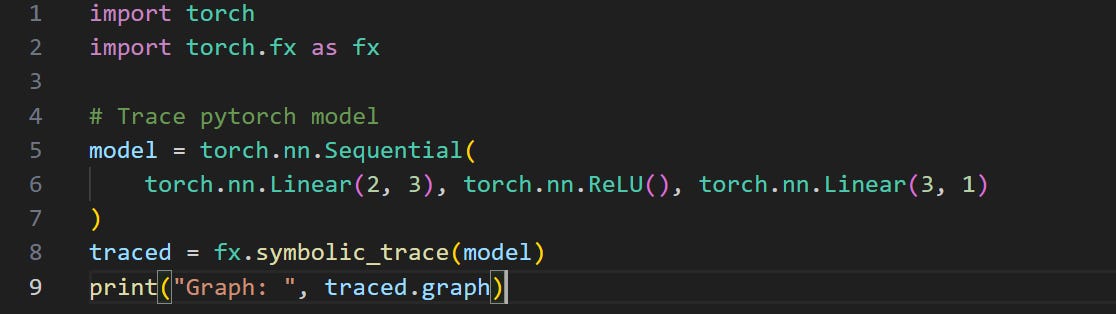
Here’s what I see when I print out the traced variable above:
Graph: graph():
%input_1 : [num_users=1] = placeholder[target=input]
%_0 : [num_users=1] = call_module[target=0](args = (%input_1,), kwargs = {})
%_1 : [num_users=1] = call_module[target=1](args = (%_0,), kwargs = {})
%_2 : [num_users=1] = call_module[target=2](args = (%_1,), kwargs = {})
return _2Note how this is reasonably similar to a MLIR dialect. We see operations with return values, arguments, etc. Thus, we can create a Python function that can transform this graph into MLIR. Keep in mind that we only need to support a few pytorch modules I showed in the code snippet above.
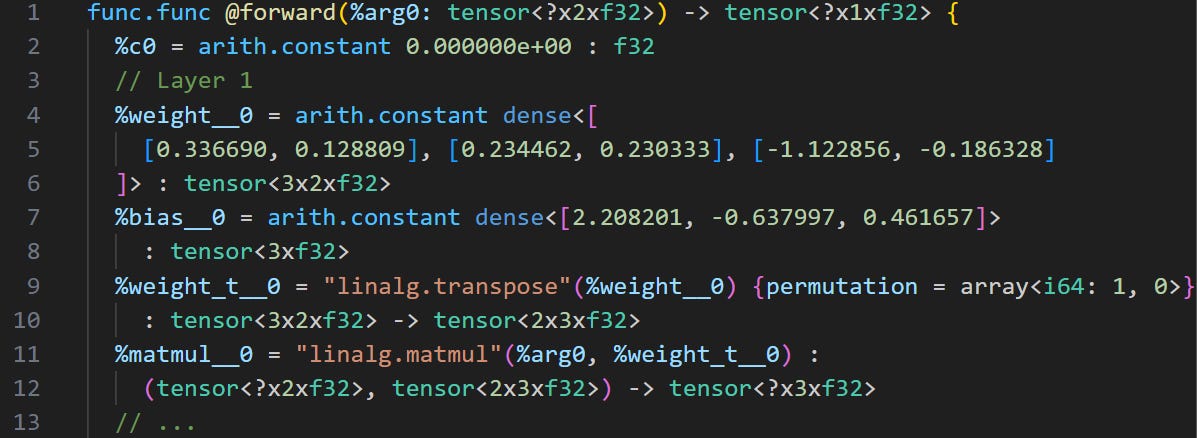
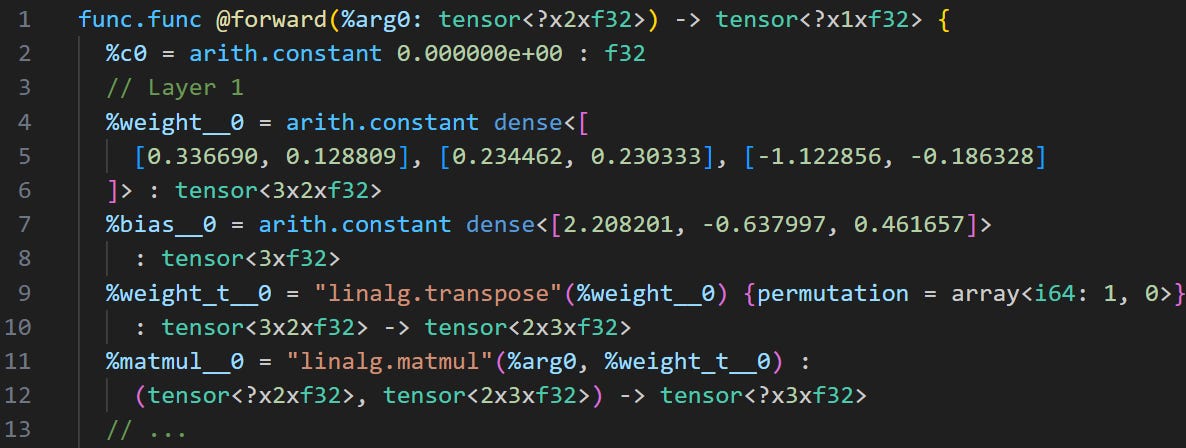
Still, even our restricted converter ends up being pretty complicated. The code I used in the end was around 100 lines of Python. It produced the following MLIR using the linalg and arith dialects:
Optimising MLIR
Now that we’ve turned our Pytorch code into MLIR, we can run standard MLIR optimisations to improve the code. We run different optimisations in ‘passes’. A pass is a single optimisation that modifies the MLIR. Passes run in sequence to improve the code incrementally.
Common Optimisations
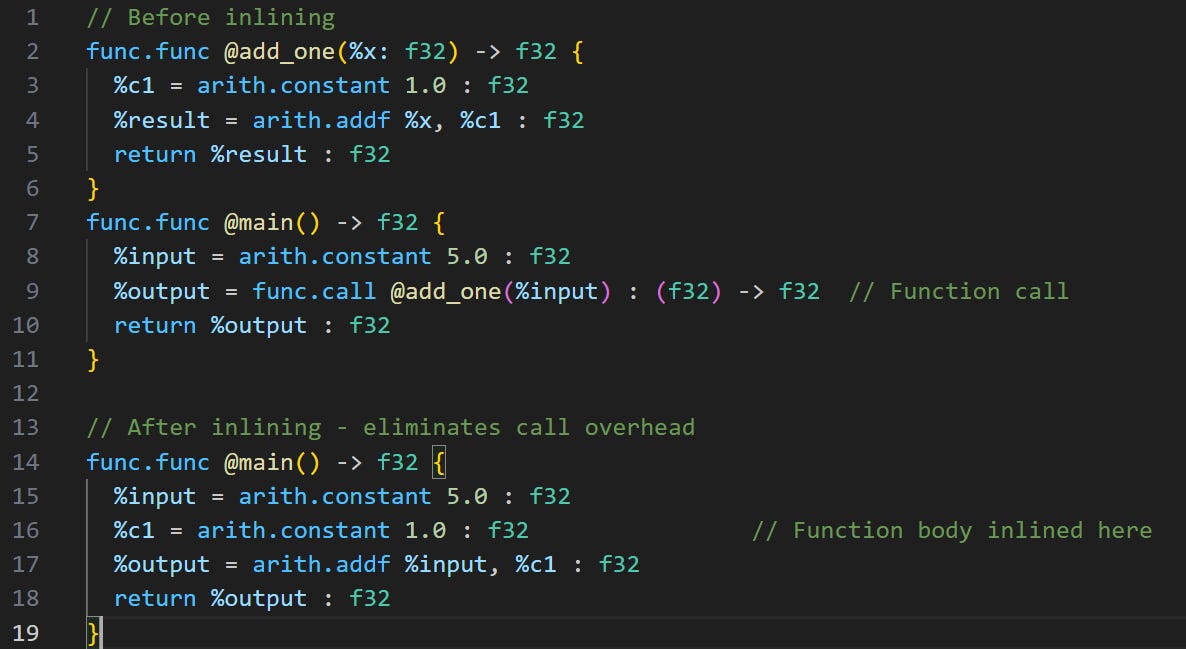
1. Inlining - Replace function calls with function bodies (reduces call overhead)
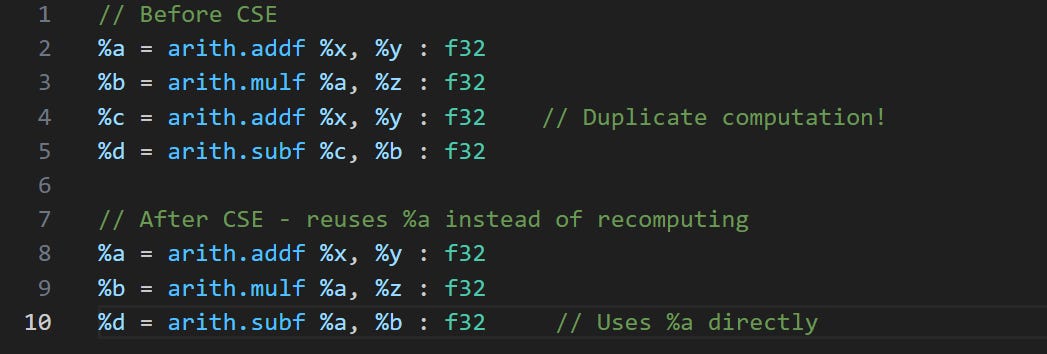
2. Common Subexpression Elimination (CSE) - Reuse identical computations to avoid redundant computations.
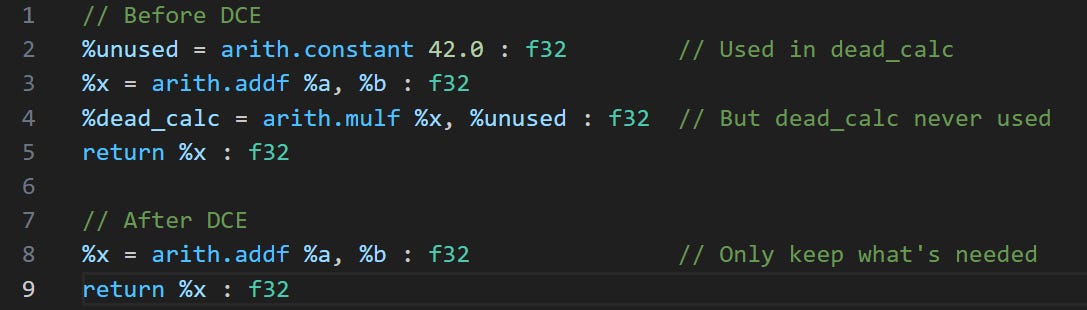
3. Dead Code Elimination - Remove unused operations (reduces memory/compute)
Enabling Optimisations with Traits/Interfaces
Optimization passes need to understand what each line of code ‘means’ to transform it. For example, when we eliminated the dead code above, we saw that a multiplication was being done, but it wasn’t being returned. We intuitively know that the multiplication didn’t impact any other part of the code. For optimisation passes to know this, however, we have to tell them about the mathematical/computational properties of the arith.mulf operation.
One example of a computational property is a ‘side effect’:
Side effects: Operations that modify memory, I/O, etc.
Pure operations: No side effects, safe to eliminate if unused

To note properties like side effects, we specify traits in the C++ code. At a high level, these are just a list of annotations for each operation. Ex: “FYI multiplication doesn’t read memory, write memory, or affect I/O. It’s also commutative and associative.” Or in more boring C++ format:

The only problem with traits is that they’re simple yes/no labels. What if we want to know more custom behaviour about an operation in the MLIR theme of creating customisable behaviour for domain-specific applications? This is where we implement interfaces: entire functions with arbitrary logic to tell us an operations’ properties.
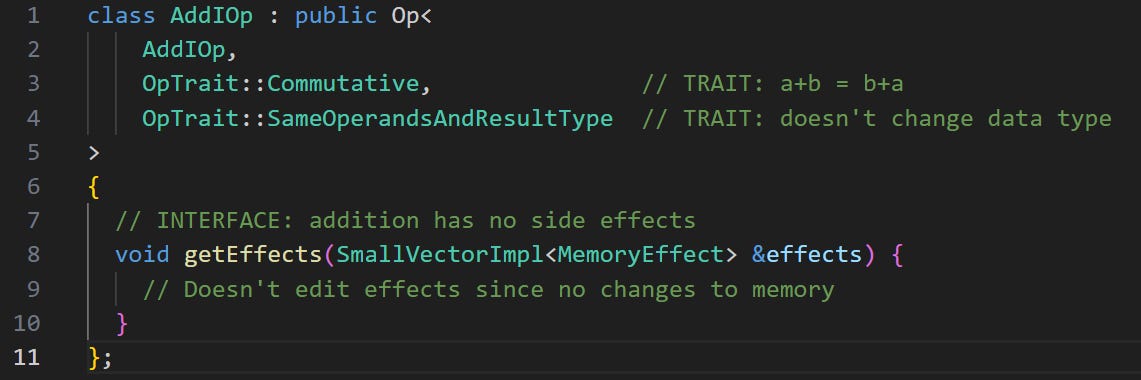
Without traits/interfaces, passes would need hardcoded lists of “safe” operations for certain transformations. This is unmaintainable as dialects grow. With traits and interfaces, we can implement logic for optimisation passes. Ex: Here’s a code snippet that shows off dead code elimination logic

Lowering MLIR
After/while doing several optimisation passes on the MLIR, we can use progressive lowering to move the MLIR through convenient dialects towards hardware-specific machine code. In this article, we started with standard Pytorch code. We turned that into MLIR with the linalg/arith dialects to optimise it:
Next, we can turn the linalg/arith dialect MLIR into LLVM IR. We’re doing this since MLIR is built on top of LLVM and LLVM has preexisting code (AKA a backend compiler) for final code generation. To generate LLVM IR, I ran the mlir-translate command line tool after running various optimisations on the MLIR via mlir-opt:
mlir-opt --convert-linalg-to-loops --convert-scf-to-cf --convert-arith-to-llvm --convert-func-to-llvm --finalize-memref-to-llvm --reconcile-unrealized-casts torch.mlir | mlir-translate --mlir-to-llvmir -o torch.llFinally, I used clang to turn the LLVM IR file into a binary executable:
clang -O2 torch.ll -o torch_model.exeKey Takeaways
MLIR: Flexible IR framework for domain-specific compilers (like for AI accelerators)
Operations: the basic, customisable building block for MLIR.
Dialects: Define custom operations and syntax for your domain
Progressive lowering: High-level → Standard → LLVM → Machine code
Optimization passes: Use traits/interfaces for safe transformations